3D裝箱問題
最近遇到一家客戶的集批設備必須考慮容積限制,所以順便google下原來這有專
有名詞叫做裝箱問題(3D BIN Packing)。git上也有不少這類的程式,也看了不
少paper,最多應用的paper都是船舶貨櫃業,想一想也是,多裝一個櫃成本多
很多,才會衍生求解此問題的價值。
最後在google上找到一個神人用excel寫的,還附帶用excel話的3D圖(超屌)
以下是程式大概的邏輯
應用演算法:large neighborhood search
1.先排序itemtype,排完一種後再換一種堆疊
2.Itemtype要先依照可堆最多個原則選擇擺放哪一面(考慮6個面)
3.考慮長寬高,重量限制,某item與某item是否可在同容器的限制
4.效益高的item先放,成本低的容器先選
5.迭代:跑機率一半從最佳解開始變形,一半從目前解開始變
這個演算法針對特定行業問題有優勢,因為可以運用行業domain寫業務邏輯
再加上版身演算法的迭代求解過程通常可以找到不錯的解。
題外話,測試時發現一個簡單的問題100個A,100個B,如果箱子全部用A可以得
到最佳解,但只要混了B就有機率填不滿容器(箱子),這是此演算法的特性,
他會從目前的解一直變形,也就是說目前的解如果走錯路之後就會一直錯下去。
針對此問題的解法是增加業務邏輯,在迭代求解前先用單一item(A或B)是否
可以得到最佳解,不行再進入演算法的迭代過程。
最後花了3天的時間把exce的code移植成C#版本,畫圖的部份則改用WPF的
3D模型來實作內部有的寫法是因為vba的限制,其實搬到C#可以用更好的寫法,
目前列第二階段再調整
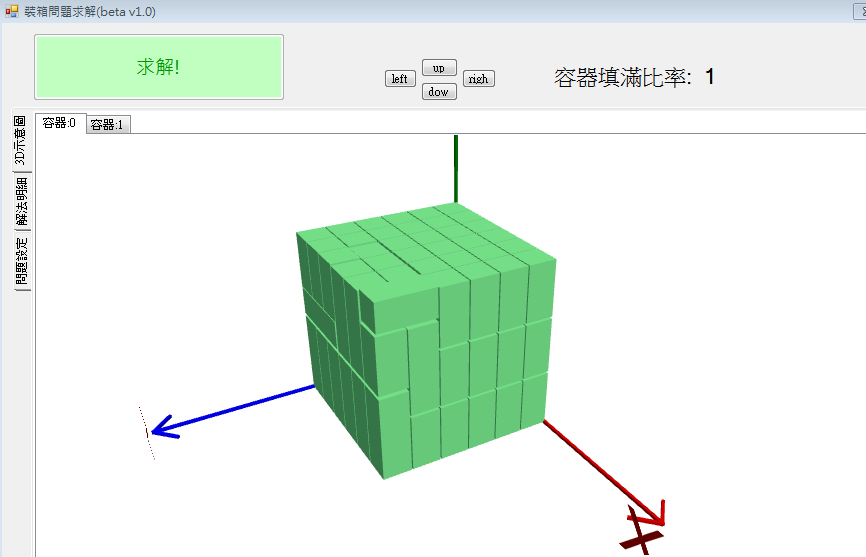
以下是目前的畫面。
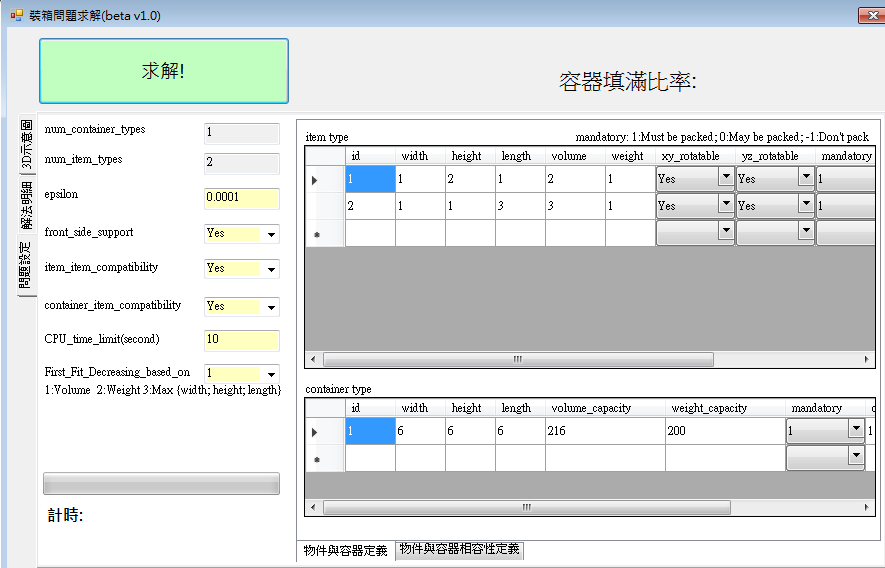
這個3D模型也是google找來的,我只修改部份程式碼(丟要畫幾個圖形及座標)
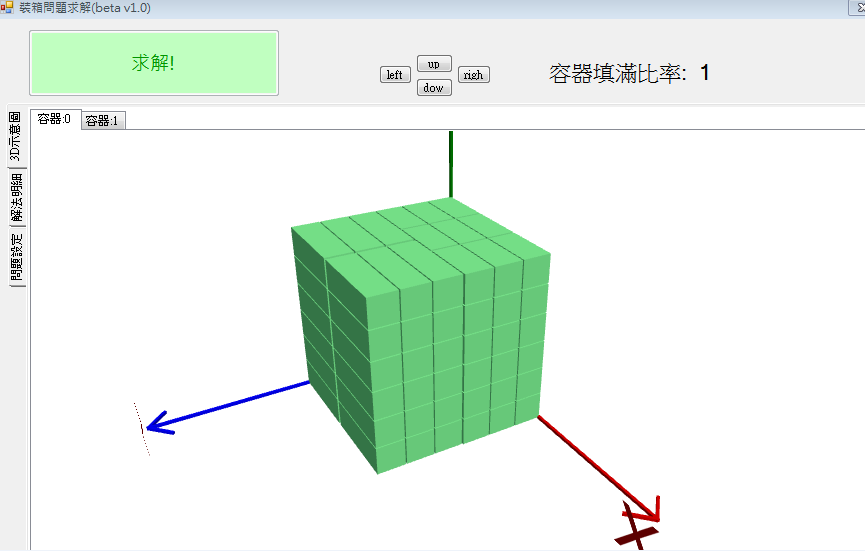
雖然滿足率都是1,但是看圖形可以發現組合不一樣