GA應用在排程
以下章節摘錄自WIKI對於GA原理的說明:
在遺傳演算法裡,最佳化問題的解被稱為個體,它表示為一個變數序列,叫做染色體或者基因串。染色體一般被表達為簡單的字串或數字串,不過也有其他的依賴於特殊問題的表示方法適用,這一過程稱為編碼。首先,演算法隨機生成一定數量的個體,有時候操作者也可以干預這個隨機產生過程,以提高初始種群的品質。在每一代中,都會評價每一個體,並通過計算適應度函式得到適應度數值。按照適應度排序種群個體,適應度高的在前面。這裡的「高」是相對於初始的種群的低適應度而言。
下一步是產生下一代個體並組成種群。這個過程是通過選擇和繁殖完成,其中繁殖包括交配(crossover,在演算法研究領域中我們稱之為交叉操作)和突變(mutation)。選擇則是根據新個體的適應度進行,但同時不意味著完全以適應度高低為導向,因為單純選擇適應度高的個體將可能導致演算法快速收斂到局部最佳解而非全域最佳解,我們稱之為早熟。作為折中,遺傳演算法依據原則:適應度越高,被選擇的機會越高,而適應度低的,被選擇的機會就低。初始的資料可以通過這樣的選擇過程組成一個相對最佳化的群體。之後,被選擇的個體進入交配過程。一般的遺傳演算法都有一個交配概率(又稱為交叉概率),範圍一般是0.6~1,這個交配概率反映兩個被選中的個體進行交配的概率。例如,交配概率為0.8,則80%的「夫妻」會生育後代。每兩個個體通過交配產生兩個新個體,代替原來的「老」個體,而不交配的個體則保持不變。交配父母的染色體相互交換,從而產生兩個新的染色體,第一個個體前半段是父親的染色體,後半段是母親的,第二個個體則正好相反。不過這裡的半段並不是真正的一半,這個位置叫做交配點,也是隨機產生的,可以是染色體的任意位置。再下一步是突變,通過突變產生新的「子」個體。一般遺傳演算法都有一個固定的突變常數(又稱為變異概率),通常是0.1或者更小,這代表變異發生的概率。根據這個概率,新個體的染色體隨機的突變,通常就是改變染色體的一個位元組(0變到1,或者1變到0)。
經過這一系列的過程(選擇、交配和突變),產生的新一代個體不同於初始的一代,並一代一代向增加整體適應度的方向發展,因為總是更常選擇最好的個體產生下一代,而適應度低的個體逐漸被淘汰掉。這樣的過程不斷的重複:評價每個個體,計算適應度,兩兩交配,然後突變,產生第三代。週而復始,直到終止條件滿足為止。一般終止條件有以下幾種:
演算法
· 選擇初始生命種群
· 迴圈
o 評價種群中的個體適應度
o 以比例原則(分數高的挑中機率也較高)選擇產生下一個種群(輪盤法(roulette wheel selection)、競爭法(tournament selection)及等級輪盤法(Rank Based Wheel Selection))。不僅僅挑分數最高的的原因是這麼做可能收斂到局部的最佳點,而非整體的。
o 改變該種群(交叉和變異)
· 直到停止迴圈的條件滿足
GA參數
- 種群規模(P,population size):即種群中染色體個體的數目。
- 字串長度(l, string length):個體中染色體的長度。
- 交配概率(pc, probability of performing crossover):控制著交配算子的使用頻率。交配操作可以加快收斂,使解達到最有希望的最佳解區域,因此一般取較大的交配概率,但交配概率太高也可能導致過早收斂,則稱為早熟。
- 突變概率(pm, probability of mutation):控制著突變算子的使用頻率。
- 中止條件(termination criteria)
以下是運用GA解決排程問題的心得:
第一個挑戰的是射出行業的射出製程,主要挑戰是訂單達交與連批,此行業特性是機台很
多,製程需要搭配使用模具,換線生產必須要有很長的整備時間,例如2~4小時清洗的時
間,所以連批(或稱併批生產,節省整備時間)就顯得非常重要。
一開始model的參數
- 種群規模(P,population size):50
- 字串長度(l, string length):3400
工單有1700張,以工單順序編碼成字串,另外將選擇的機台機率也編碼成字串,兩者相連成
3400長度的字串。下圖為編碼的示意圖。
- 交配概率(pc, probability of performing crossover):0.8
- 突變概率(pm, probability of mutation):0.1
- 中止條件(termination criteria):跑500~1000代
流程與作法說明
一開始初始化(隨機)50個基因編碼字串,然後跑Fitness函數依Fintess值排序,其中Fitness函
數是用來評估這組解的好壞,最開始是用節省的連批總時間,也就是說其實沒有考慮訂單交
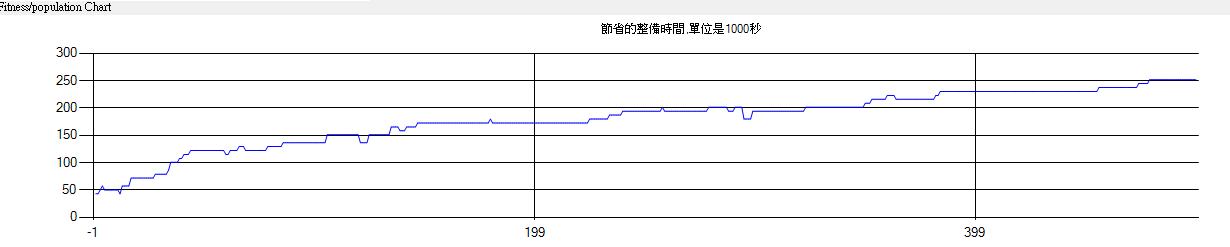
期,得到的結果如下圖,可以看得出來跑到500~1000之間就進步的很緩慢,花費時間30分
鐘,後續就沒有再嘗試更多代了,因為工單多所以評估解花費不少時間(是還可以嘗試用多
執行緒,不過改程式要花不少時間就懶得動了-.-)。大約省252000秒的整備時間,換算是35
次,工單有1700張,這解明顯不合格,跟DS引擎相比差距頗大(107個連批),另外GA達交率
是50%,DS達交率為81%。DS使用排程規則在1分內排出結果。
跑500代
跑1000代

DS排程甘特圖
GA建模方式調整
- 連批優先+適應值=總節省整備時間
選機台不採用基因編碼中的機率,而是根據工具前個工單排在哪台設備,欲排工單就接著
排,得到結果為連批141,達交率50%。
- 交期達交先>連批,如果隨機跟強制連批兩個都延遲,那就選強制連批的,適應值=總節省整備時間(50%)+延遲率(50%)
機率選機台跟跟著前OP的機台兩者,看誰交期達交就選該機台,如果兩個都延遲就選連
批的,適應值則是將兩個指標(總節省整備率(50%)+延遲率(50%))各佔比50%的組合
下得到適應值,得到結果為連批112,達交率62%。
第二種案例(SMT正背版+訂單達交)
基因編碼改為工單順序+BOT與TOP的機台機率,發現結果還是比DS糟,後來改為只用工單順序,機台則是選擇最早完工的機台,適應值則為BOT完工後TOP要在12小時內開工,且需要考慮訂單達交,這邊有兩個目標,這次改用歐式距離當多目標的適應值,這次在工單張數在115張,結果如下,可發現GA結果有比DS好一點點,推測應該是工單張數不多的關係。
DS
BOT-TOP遵守12小時限制:115/115
達交:51/115
makespan:2019/9/19
GA
BOT-TOP12小時限制:115/115
達交:56/115
makespan:2019/09/10 04:30:00
BOT-TOP遵守12小時限制:115/115
達交:51/115
makespan:2019/9/19
GA
BOT-TOP12小時限制:115/115
達交:56/115
makespan:2019/09/10 04:30:00
總結
GA在單一指標下有比較好的結果且容易收斂,但在多目標下較難收斂到滿意解,另外就是基
因編碼單一指標也比較容易收斂,同時把機台機率放進基因編碼則會讓結果更發散。

沒有留言:
張貼留言